Hi all,
I am a beginner at this. I am trying to use Automator to scrap text data from several web pages. I want the Automator to get the web page from safari, get all the link URLs from this web page that contain particular texts in their URL and then extract the text from all these link URLs. The Automator workflow I am working with keeps returning the error and I cannot understand why:
NSURLErrorDomain error -999.
The website I am scrapping is http://www.myneta.info/ls2014/. The link URLs that I am interested in contain the text " http://www.myneta.info/ls2014/index.php?action=show_candidates&constituency_id= " in them.
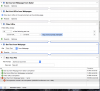
Attached along is a snapshot of the workflow with the error. Any help will be greatly appreciated.
Thanks,
Tushar.
I am a beginner at this. I am trying to use Automator to scrap text data from several web pages. I want the Automator to get the web page from safari, get all the link URLs from this web page that contain particular texts in their URL and then extract the text from all these link URLs. The Automator workflow I am working with keeps returning the error and I cannot understand why:
NSURLErrorDomain error -999.
The website I am scrapping is http://www.myneta.info/ls2014/. The link URLs that I am interested in contain the text " http://www.myneta.info/ls2014/index.php?action=show_candidates&constituency_id= " in them.
Attached along is a snapshot of the workflow with the error. Any help will be greatly appreciated.
Thanks,
Tushar.